Last updated on October 6, 2024 pm
R语言数据分析常用操作 零、内存管理
及时清除不需要的变量,如超大的原始矩阵
更新了新的Rstudio 版本(2023.06.1+524 ) 后,可直接rm()
1 2 rm(exp_of_gene,Lung_sum_Expr) # rm() 清除环境变量
一、常用操作
重复值操作
重命名
1 2 3 4 5 6 7 8 9 dfnew <- df[ ! duplicated( df) , ] sum ( duplicated( df$ id) ) ( df$ id) ( duplicated( df) ) ( df) [ 1 ] = 'a' names ( var_test) [ names ( var_test) == "y_slide_mm" ] <- "Y"
删除
1 2 3 4 5 6 7 8 9 ( dplyr) <- select( data, - 3 ) <- select( data, - lieming) <- select( data, - c ( lieming1, lieming2) )
二、绘图
(1)调整坐标轴刻度
scale_x_continuous
1 plot( ) + scale_x_continuous( breaks= seq( 0 , 10 , 1 ) ) 调整X轴刻度
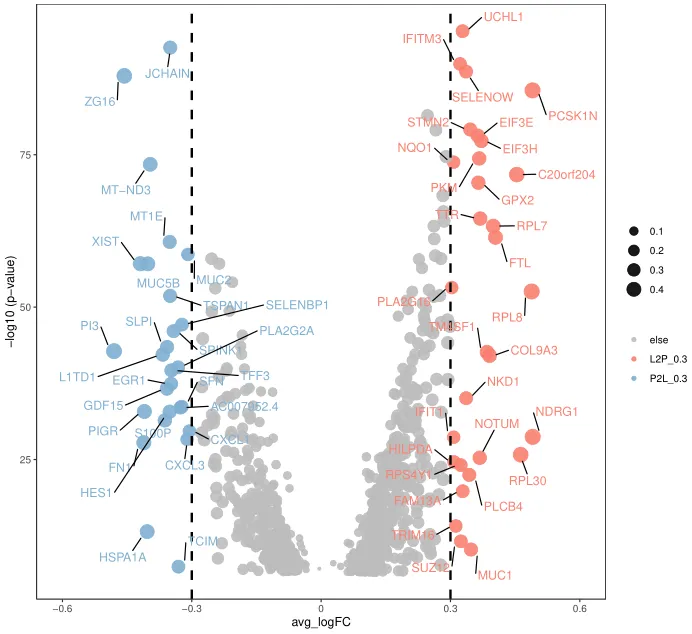
(2)散点、火山图标签
ggrepel::geom_text_repel()
1 2 3 4 5 6 7 8 9 10 11 library(ggrepel)
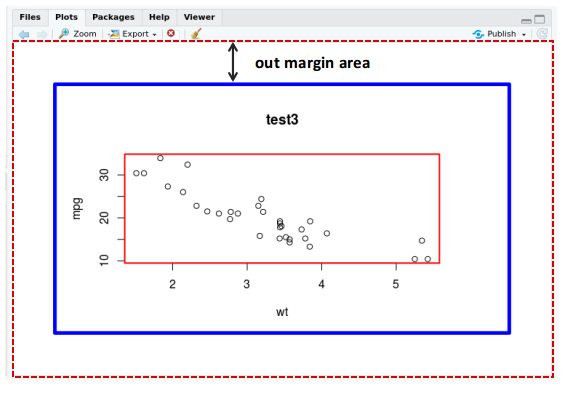
(3)调整绘图页面边距,坐标轴字显示不全
par(mar=c(5,5,5,5))默认外边框的大小为mar=c(5.1,4.1,4.1,2.1), 分别对应下,左,上,右四个外边框
R绘图区域(如上图),主要分为两部分
一是外围边距(out margin area,oma);
二是绘图区域,绘图区域又细分为两个部分:绘图边距margins和主绘图(main plot area)
外围边距 可使用 par() 函数中的 oma 来进行设置。 oma 即 out margin area ,例如 oma=c(5,4,3,2) ,这里指外围边距分别为下边距: 5行,左边距4行,上边距3行,右边距2行,这里的行是指可以显示1行普通字体。注意,oma()设置顺序是从bottom开始,按照bottom,left,top,right方向设置,也就是从bottom开始按照顺时针方向设置。
绘图边距 (margins)可以使用par()函数中mar来设置。比如mar=c(5,4,3,2),与外围边距的设置类似,是指绘图边距分别为下边距:5行,左边距4行,上边距3行,右边距2行。参数设置顺序与oma()顺序一直,也是从bottom开始顺时针方向设置。
1 par( oma= c ( 3 , 3 , 3 , 3 ) , mar= c ( 5 , 5 , 5 , 5 ) )
三、配色网站
十六进制颜色,左侧可选各种风格
一个好用的配色网站! 毒蘑菇 - 配色
Color Palettes for Designers and Artists - Color Hunt
http://www.yinhuafeng.cn/daohang/peise/#hue_4 打开很快
四、数据
数据是否取过log 的粗略估计
1 2 3 4 5 6 <- Lung_sum_Expr[ , "TSPAN6" ] ( GEtest, breaks = 30 )
五、Tools
斜杠反斜杠转换: windows斜杠转换-在线工具
六、加快运行速度
1 2 3 4 5 6 7 #试着调用CPU多核性能-----------------